
Transformation - XPath Basic
In this microlearning, we'll introduce you to XPath and how it can be used for custom transformations in eMagiz. When the built-in transformation options fall short, XPath expressions can help you achieve precise results by navigating and manipulating XML data. We’ll cover the basics of XPath, including how to use it within eMagiz to handle complex transformations. Let’s get started with the essentials!
Should you have any questions, please contact academy@emagiz.com.
1. Prerequisites
- Basic knowledge of the eMagiz platform
2. Key concepts
This microlearning focuses on XPath Basic in the context of transformations.
With XPath Basic, we mean: Understanding on a fundamental level what XPath is, how it is used and how you can use it within the transformation tooling of eMagiz
3. Transformation XPath Basic
Sometimes the transformation tooling does not provide you with the exact correct transformation option to get the desired result in your output. For those cases, you can use a custom (handwritten) XPath expression to achieve the desired result.
3.1 What is XPath
Before we delve into the use of XPath within the eMagiz tooling let us first discuss XPath itself. XPath stands for XML Path Language.
As the name suggests it can be used to write down a certain "path" to identify and navigate nodes in an XML message.
By following this "path" you can access all elements and attributes within your input XML message.
XPath is a widely used standard with a lot of built-in functions and is a W3C recommendation
3.2 Reading and Writing XPath
The simplest XPath is /. This simply means access the root of the input message. So to access the root of your input message you write down one forward-slash (i.e. /).
If you want to access an element below the root directly you can use two forward slashes (//) to start your XPath expression.
For example, take a look at the following input message:
<Project>
<ID>1</ID>
</Project>
</Projects>
When I want to write a "path" to Projects I would only have to write down / and that is it. However, when I want to write a "path" to Project I have two options.
I can either start at the root (Absolute XPath) and navigate down from there which would give me /Projects/Project as a valid XPath expression.
On the other hand, I could also start directly at the Project element (Relative Xpath) which would give me Project as a valid XPath expression.
To expand on that example we would now like to navigate to ID. The XPath can either start at the root level (Projects) or element level (Project or ID).
So this means that in this simple example we have three alternatives to end up with the same result:
- /Projects/Project/ID
- Project/ID
- //ID
At this point you probably wonder why anyone would start their journey on the XPath "path" from the root level. Well imagine the following input message:
<Project>
<ID>1</ID>
</Project>
<Status>
<ID>1</ID>
</Status>
</Projects>
As you can see from this example taking the third option of our previous example would end up getting two results (both the ID under Project and the ID under Status).
There are also scenarios one could think of that would benefit from starting not on the root level of the input message. So always consider the context when writing down your XPath.
3.3 Absolute vs Relative XPath
As discussed in the previous segment there is a choice to be made between using an Absolute XPath (which starts at the root level) and the Relative XPath (which can start anywhere in the structure)
Below you find a summary of the main differences between both options.
Absolute XPath
- It is the direct way to find the element
- Disadvantage of the absolute XPath is that if there are any changes made in the path of the element then that XPath gets failed.
- Starts with the single forward-slash(i.e. /), which means you can select the element from the root node.
Relative XPath
- Finds the element(s) in the whole message, not considering the structure.
- Starts with the double forward-slash (i.e. //), which means it can search the element anywhere at the message.
3.4 Namespaces
To complicate things a little bit more we are now going to discuss namespaces. A namespace is a set of symbols that are used to organize objects of various kinds, so that these objects may be referred to by name.
An example of comparative nature would be:
There are in the Netherlands two cities named Hengelo. Via namespaces can we split and recognize them. The namespace that can be used to split them is using the namespace Province (Gelderland and Overijssel).
Gelderland:Hengelo & Overijssel:Hengelo
To handle namespaces while reading and writing XPath you have two options:
- Prefix
- Wildcard
3.4.1 Prefix
By defining the prefix of the namespace (i.e. sys, cdm, ns) you can refer to this prefix while reading and writing your XPath.
Let's return to our original example, only this time the input message has a namespace:
<sys:Project>
<sys:ID>1</sys:ID>
</sys:Project>
<sys:Status>
<sys:ID>1</sys:ID>
</sys:Status>
</sys:Projects>
As you can see the notation has slightly changed. A prefix has occurred before each element and attributes called sys. To separate the prefix from the name of the element or attribute a colon (:) is used.
The XPath also needs to change to get the desired result. We need to take the prefix into account. This will result in the following valid XPath options:
- /sys:Projects
- /sys:Projects/sys:Project
3.4.2 Wildcard
By using the wildcard notation, an asterisk (\*), you specify that regardless of the chosen prefix by the party for delivering the input message you will accept it.
Using the prefix makes it clearer to others in which namespaces the XPath is written.
Using the wildcard is easier as you don't have to check for every XPath you write what the prefix is and whether there is a namespace.
Therefore we see a lot of use of the wildcard when writing a custom XPath in eMagiz.
Using the wildcard will result in the following valid XPath options:
- /*:Projects
- /*:Projects/*:Project
3.5 Custom XPath in Transformation
Now that we have a basic conceptual understanding of XPath let us turn our attention towards relating this information to eMagiz.
Specifically how you can use it while transforming your messages with the help of the transformation functionality in Create.
As you saw in the previous microlearning a lot of options are already available out of the box and don't require you to write your custom XPath.
However, sometimes it is necessary to write a custom XPath.
Let us look at an example in eMagiz:
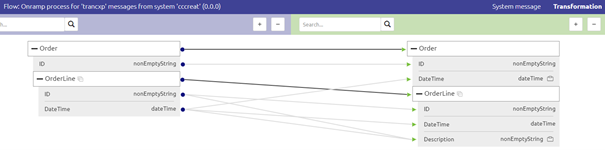
In this example, you see two notes on two attributes. One on the DateTime on Order Level and one on the Description on OrderLine level. The requirements are:
- The DateTime should be filled with the DateTime value related to the first OrderLine
- The Description should be the value for ID and the value for DateTime merged with the help of a dash (i.e. -) icon.
To make this happen we need a custom XPath. Remember the discussion on Absolute vs Relative earlier in this microlearning?
The way the transformation logic is build up helps you ensure that the correct values end up in the correct places.
What I mean by that is that the line drawn towards a certain entity in the output determines the starting point from where to reason when writing an XPath.
For example, when looking at the Order entity you see that the origin is the Order entity of the input message.
So the basic XPath eMagiz would have generated to fill in the value for DateTime on Order level would be:
- OrderLine/DateTime
This is because the starting point of our "path" is the Order entity already.
To ensure that we only place the DateTime value of the first OrderLine in the DateTime field on Order level in the output message we need to change the XPath.
To do so enter Start Editing Mode and navigate to the Transformation. In here select the option Transformation and then Custom XPath
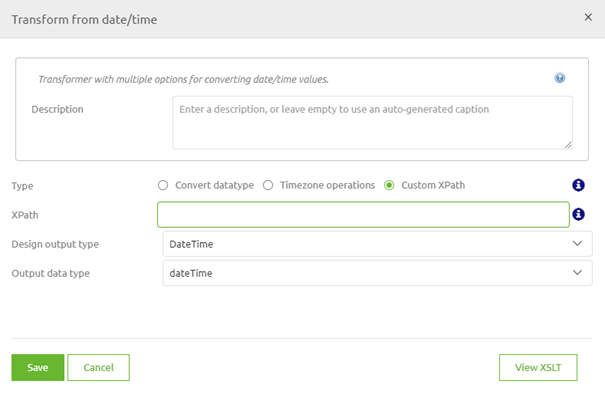
In here we need to ensure that we only take the DateTime value from the first OrderLine. To do so we need to specify which of the OrderLines we want as input.
You can specify that by using the following notation:
- [1] = the first iteration of OrderLine
- [2] = the second iteration of OrderLine
- etc.
This would change our XPath to OrderLine[1]/DateTime. So let us fill that in and press Save.
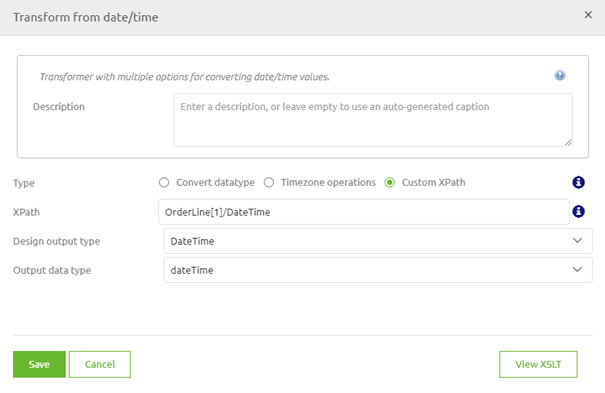
Now let us turn our focus toward the second part of this example. Remember what we said earlier.
The starting point of your "path" within a transformation is determined by the starting point of the line that is drawn to the entity you are currently working with.
In this case that is the OrderLine.
So the basic XPath eMagiz would have generated to fill in the value for DateTime on Order level would be:
- DateTime|ID
This is not quite what we want as it does not account for the dash icon that needs to separate the two values.
So, once again select the transformation option and opt for Custom XPath.
As specified before there are a lot of built-in functions available when using XPath. One of these functions is the string-join.
With a string-join, you can join two input attributes together in a certain order and separate them with the help of a divider.
This would change our XPath to string-join((DateTime, ID),'-'). So let us fill that in and press Save.
When I tested this I got the following result. In a later microlearning, we will teach you all about testing these things yourself.
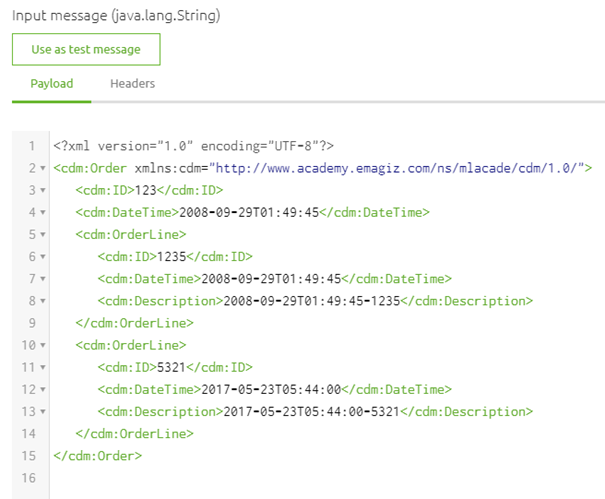
4. Key takeaways
- XPath gives you the option to navigate through an XML document in a "path" like manner
- There are various ways of setting up your XPath (Absolute vs Relative)
- Consider the namespace
- Within the transformation, the starting point of each XPath depends on where the line on entity level was drawn from