
Duplicate Detection
In this microlearning, we will introduce the relevant stateful components to configure the Duplicate Detection operation in the context of State Generation. In case you want to learn the basics of the State Generation functionality, please check out eMagiz State Generation.
Should you have any questions, please get in touch with academy@emagiz.com.
1. Prerequisites
- Basic knowledge of the eMagiz platform
- Basic knowledge of the eMagiz State Generation
2. Key concepts
In this microlearning, we will introduce the relevant stateful components to configure the Duplicate Detection operation in the context of State Generation functionality.
- By Duplicate Detection, we mean: A form of operation in which we identify and monitor the flow of messages over time so that if all or some part of any new messages match all or some part of those messages previously received, we can tag them as duplicates and take appropriate action such as discarding them.
There are some check points to think about beforehand when setting up the Duplicate Detection operation:
- How should past messages be stored for incoming messages to compare? For how long these past messages will be stored?
- What is the condition for incoming messages to be tagged as duplicates? Which part of the messages will be compared to indicate duplicates?
- When a duplicate is detected, what is the action to be taken and how to set up such an action?
3. Setting up Duplicate Detection operation
To configure the Duplicate Detection operation, you first set up the component to check if the incoming message is a duplicate or not, and then the action when a duplicate is detected. If state persistence during runtime shutdowns or restarts is a requirement, then you can also set up the storage to maintain the states.
3.1 Detecting Duplicates
First of all, you can start with setting up the component that is responsible for detecting duplicating messages and then either mark these messages as duplicates or discard them. eMagiz provides a support object that can do this, namely, the Duplicate Detector that you can add into your flow via the standard manner by searching for "Duplicate detector".
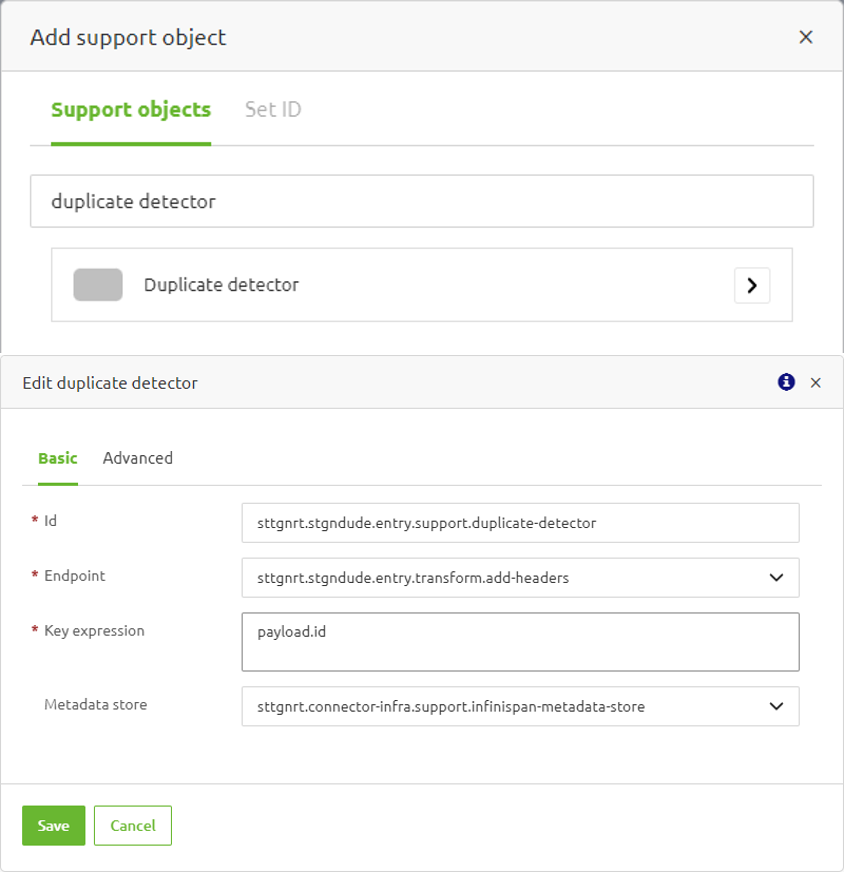
The idea here is to apply this support object to any component in your flow that has an input channel, allowing that component to check if the incoming message resembles any or some part of the state data stored in the metadata store. As shown in the screenshot above, from the Endpoint dropdown menu, you can do this by selecting the flow component to which you want to apply this support object. Next, using a SpEL expression in the Key expression field, you can then define which part of the incoming message should be compared with the key of the state data that are already stored in the metadata store. Afterwards, you can either select a metadata store support object you have created if you require state persistence, or leave it empty, which will default to an in-memory store that may result in data loss during runtime shutdowns or restarts.
Let us take the screenshot above as an example. We evaluate an incoming payload based on its id field and compare it with the existing state data in the store that has similar id as its key. At a certain point, there is an incoming payload such as {"id":"123","name":"John"}. If there is no state data with the key "123" stored in the metadata store yet, and assuming that we set payload.name as the Value expression, then a new state data entry of <123:"John"> will be stored (note that the metadata store stores state data as key-value pairs, and 123 here is the key and "John" is the value). This means that if another payload such as {"id":"123","name":"Doe"} arrives, it will be considered a duplicate because the Duplicate Detector could find an existing state data with the same key as the id field of the incoming payload.
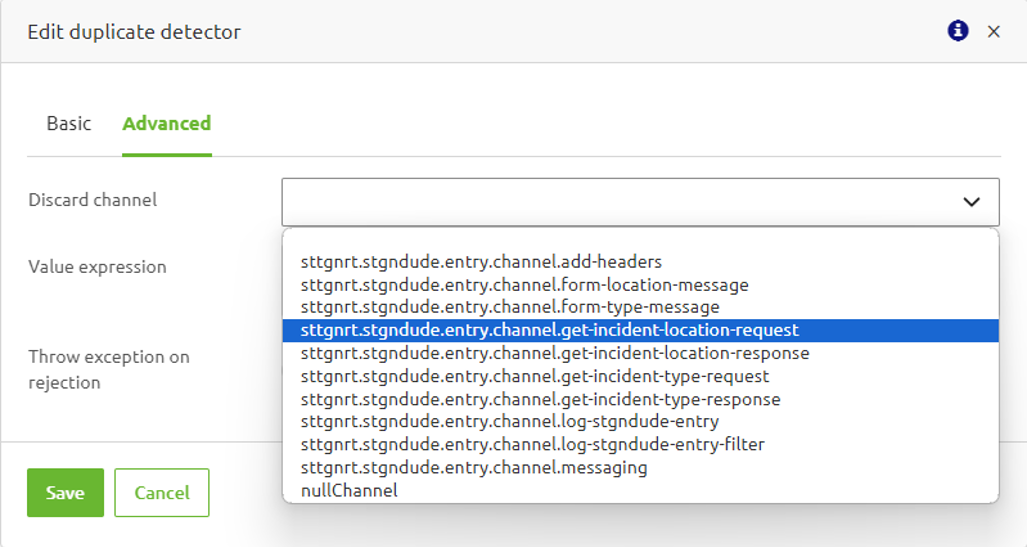
3.1.1 Handling Duplicates
Once a message is considered a duplicate, the next step is to define the action to take when such a duplicate is detected. To do this, go to the Advanced tab of the Duplicate Detector support object, where you will find the Discard Channel configuration. See the screenshot below for an example for this.
3.2 Storage Mechanism for State Persistance
As discussed above, in the case that you require persistence to your state (storing to disk instead of in-memory), then you need to link a Metadata store to your Duplicate Detector support object. Therefore, you will need to set up these support objects as well if you have not done so already:
- Infinispan cache manager
- Infinispan metadata store
Once you have done so, you can set the "Simple cache" option in your metadata store to "no" and then set the "Persistent" option to "yes". For more information on configuring these support objects and understanding their settings, please refer to this State Persistence microlearning.
4. Key takeaways
- With State Generation, you can compare incoming messages to past state data to detect any changes that may trigger specific actions.
- To set up a State Generation - Duplicate Detection operation, you need to configure a Duplicate Detector support object to compare parts of incoming messages with the stored state data, and a flow component to attach the duplicate detector for executing the detection.
- In the case that you require state persistence, you need to set up an Infinispan Metadata Store and its Infinispan Cache Manager and then link the store to your Duplicate Detector.
- To minimize the hurdles and speed up the process of setting up a State Generation - Duplicate Detection operation, we recommend using a store item that is available here.
5. Suggested additional readings
If you are interested in this topic and want more information on it, please read the help text provided by eMagiz and read the following microlearning on the related topic: