
Volume Mapping (On-premise)
When you need to read and write files from an on-premise disk, you need to know the path in which the data is stored and ensure that the docker container in your runtime(s) running has access to this path. There are several ways of dealing with this challenge. This microlearning will discuss the various alternatives and best approaches in these scenarios.
Should you have any questions, please contact academy@emagiz.com.
1. Prerequisites
- Basic knowledge of the eMagiz platform
2. Key concepts
This microlearning centers around learning how to correctly set up your volume mapping so you can exchange file-based data on-premise.
By volume mapping, we mean creating a configuration through which the docker container can read and write data on a specific path on an on-premise machine. Note that the data can also be stored inside the docker container when (1) the other party writing or reading the data can access this path or (2) when the data is only relevant within the context of eMagiz.
There are several options for volume mapping for your on-premise machine.
- Machine volume
- Bind mount
- Network volume
- Temporary file system
- Named pipe
3. Volume Mapping (On-premise)
When you need to read and write files from an on-premise disk, you need to know the path in which the data is stored and ensure that the docker container in your runtime(s) running has access to this path. There are several ways of dealing with this challenge. This microlearning will discuss the various alternatives and best approaches in these scenarios.
There are several options for volume mapping for your on-premise machine.
- Machine volume
- Bind mount
- Network volume
- Temporary file system
- Named pipe
Below, we will explain the differences between the various options available for your volume mapping. But before we do this, we explain how to set up this configuration within eMagiz. First, you must navigate to Deploy -> Architecture on the model level. This overview lets you access the Volume mapping per runtime deployed on-premise. And then, you can right-click on the runtime to access the context menu.
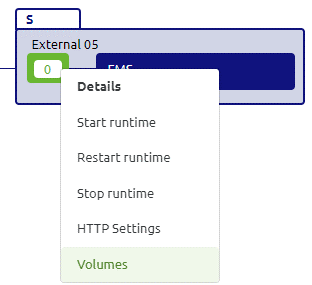
Right after you click this option, you will see the following pop-up. In this pop-up, you can define the machine-level, runtime-level, and network-level volumes (more on this volume levels later). This pop-up page is the starting point for configuring your volume mapping. We will walk through each available option and explain how they work and should be configured.
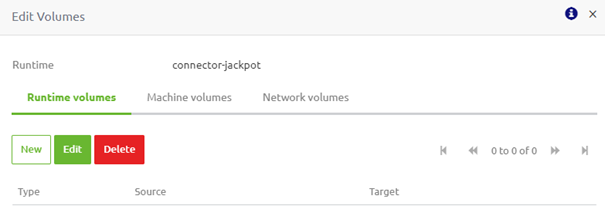
3.1 Volume
The first Type available to you is volume. With this option, you create one or more folders on Docker relevant to that runtime to read and write persistent data. To configure this Type, you need to link the runtime volume to a machine volume (or network volume) you can create within the same pop-up. This means you can re-use a "Machine volume" or a "Network volume" over multiple runtimes (i.e., containers). We first need to define a machine (or network) volume to do so. Once we have done that, we can learn how to link the volume to the machine or network volume.
3.1.1 Define Machine Volume
So, we first open the tab called "Machine volume." Then, by pressing the "New" button, we can define a new "Machine volume." In the following pop-up, we can specify the name of a machine volume and tell whether the volume already exists on your docker installation.
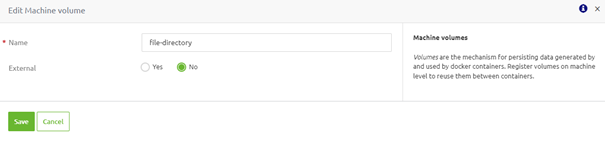
Once you have done so, we press "Save" and switch back to the "Runtime volumes" tab.
3.1.2 Define Network Volume
So, we first open the tab called "Network volume." Then, by pressing the "New" button, we can define a new "Network volume." In the following pop-up, we can specify the name of a machine volume and configure the relevant information for a network volume. In most cases, a CIFS is used, and the only pertinent options that need to be filled in are the host, path, username, and password.
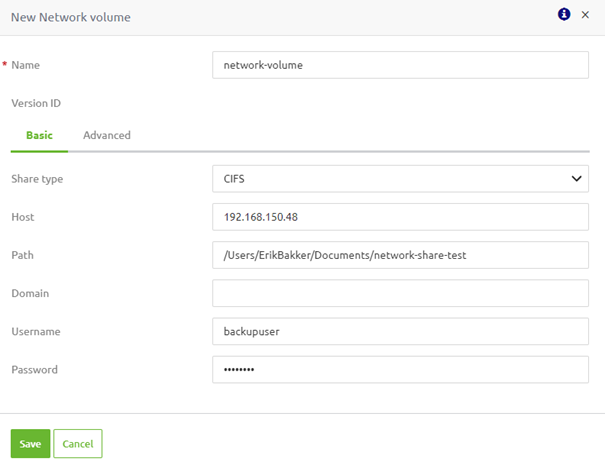
Once you have done so, we press "Save" and switch back to the "Runtime volumes" tab.
3.1.3 Link Volume
In the "Runtime volumes" tab, we push the "New" button to create a new "Runtime volume." In the following pop-up, we must select the Type we want to use. For this example, we use the Type called "Volume."
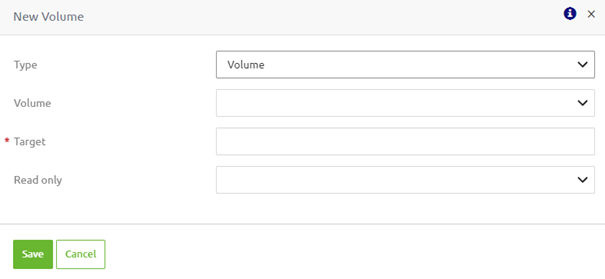
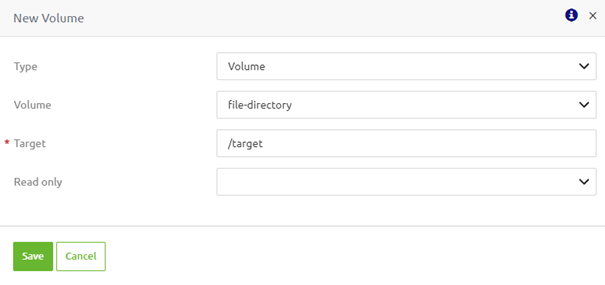
The first thing we need to select is the "Volume." Once we have chosen our "Volume," we must set the Target specific for this runtime. This target defines the second part of the path to which the runtime will gain access. For example, when you fill in "/target", we can combine this with the "Volume" name to arrive at the correct directory from which eMagiz needs to read data (or write data to). So, in our case, in which we link the volume to the machine volume we created earlier, this would be "/file-directory/target."
The last setting we need to configure is to define the rights we will grant our runtime on the volume we create. The default setting is read/write rights for the runtime, which is usually sufficient. The result of following these steps will be the following.
3.2 Bind mount
An alternative option to read and write persistent data is the "Bind mount" option. We generally advise using the "Volume" option because they perform better, and bind mounts depend on the host machine's directory structure and OS. However, only some external systems can adapt to this that easily. For example, the "Bind mount" option can interest your use case.
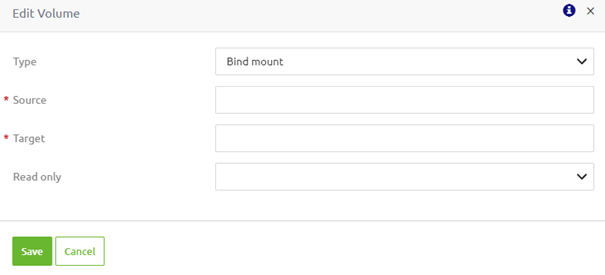
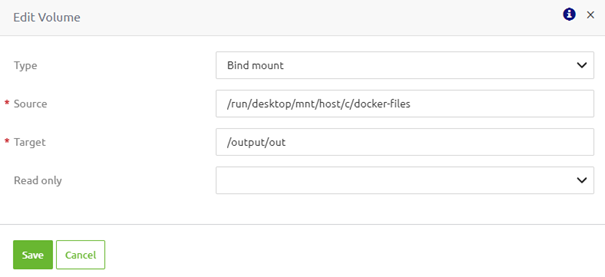
To configure a "Bind mount," you need to define a source and a target directory linked to each other. The source directory represents the directory on your local system (that might already be used currently to exchange files). The target directory defines a directory on your docker installation that the runtime can access.
3.3 Temporary file system
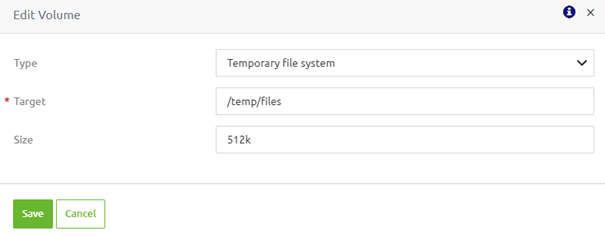
The temporary file system option is for you if you do not want to work with persistent data but require non-persistent data. This way, you can increase the container's performance by avoiding writing into the container's writable layer.
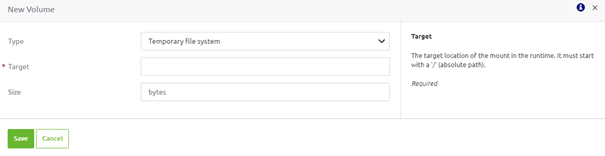
To configure this option, you need a target location. On top of that, you can define the maximum size of the temporary file system.
3.4 Named pipe
A named pipe is a named, one-way or duplex pipe for communication between the pipe server and one or more pipe clients. All instances of a named pipe share the same pipe name, but each instance has its own buffers and handles, and provides a separate conduit for client/server communication. Any process can access named pipes, subject to security checks, making named pipes an easy form of communication between related or unrelated processes.
*The named pipe option can be selected, but we yet have to see a valid use case within the context of eMagiz for using this option. Therefore, we won't discuss this option further in this microlearning.
3.5 Deployment consequences
4. Key takeaways
- File-based communication on-premise changes in the new runtime architecture
- There are two ways to store persistent data
- Volume
- Bind mount
- The Volume option is considered the best alternative because they have better performance, and bind mounts are dependent on the directory structure and OS of the host machine
- Before deploying, ensure that the various sources in your configuration exist and that access is granted to avoid problems while deploying.
- The Temporary file storage option is the way to go when dealing with non-persistent data.