
Grouping - Configuration
eMagiz flows, or more specifically, the flow's inbound component(s), can be grouped. The effect is that you can later in Deploy, control them as one entity. This is mainly beneficial when faced with substantial maintenance or outage of systems connected to your eMagiz model.
Building on this functionality, you can even configure the group to run in an active/passive failover mode when you activate the multiple runtimes option on your runtime, and each separate runtime is deployed on another machine. The failover functionality is not only relevant in cases of server maintenance. It can also assist you when you want to exchange data with a system that allows only one active connection. Should this connection be business-critical, you can use this failover functionality to create a passive failover situation that will take over when the active connection breaks down (regardless of the reason).
In this microlearning, we will focus on configuring the flow to group various inbound components and configure the flow (including the infra) if you want to activate the active/passive failover configuration.
Should you have any questions, please get in touch with academy@emagiz.com.
1. Prerequisites
- Intermediate knowledge of the eMagiz platform
2. Key concepts
This microlearning describes how to configure (parts of) your flow(s) to set up the grouping and, if needed, the failover functionality on the flow level. The grouping functionality is relevant when faced with maintenance and outages of systems connected to your model. The failover functionality assists in that case and allows you to have a fallback option on an active connection.
3. Flow Configuration
3.1 Grouping
To configure grouping, we need to open the flow designer of the flow in Create. We want to edit and enter "Start Editing" mode. On the inbound component(s) in the flow, we now have an "Advanced" tab that allows you to configure the grouping information.
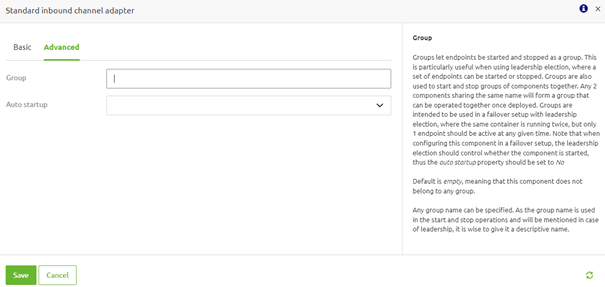
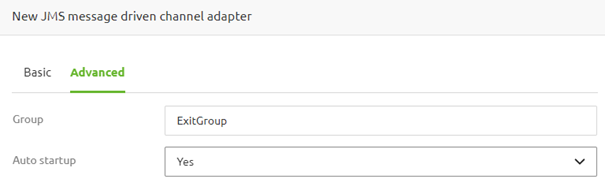
Once on the "Advanced" tab, you must define the group name. You can determine the group name if this is the first flow you change. In all subsequent flows, you want to add to the same group, you must use the same group name.
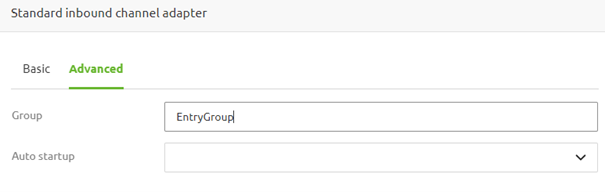
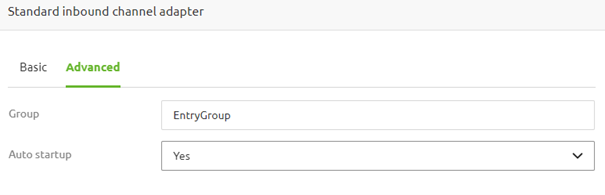
Once filled in, ensure that the auto startup configuration is set to Yes to ensure that, on default, all flows within the group start up when the container is started.
Within a runtime context, you can add multiple groups that can be stopped and started separately from each other. In this example, we would also like to have a group for our exits to stop them if the connecting system undergoes maintenance or is down to store the messages in the queue.
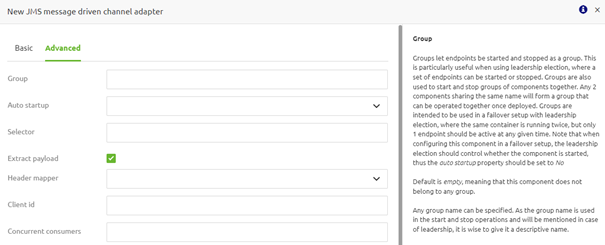
3.2 Failover
If you want to expand the grouping functionality to include an active/passive failover component, you need to change the settings on the inbound component. Apart from specifying the group name, you need to configure the auto-startup option on "No" so the failover configuration can take the correct actions in all situations.
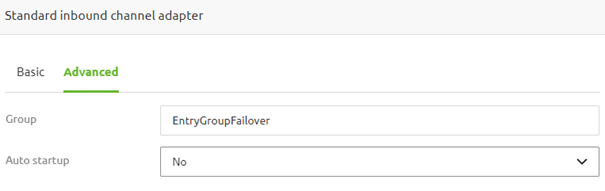
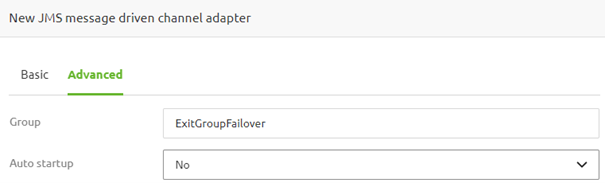
3.3 Failover Infra
The configuration of the infra flow of the runtime for which you want to configure the failover is detailed and only works if you configure all support objects correctly. Although we explain the various steps in the documentation, we advise utilizing the store item we created for this that will guide you in setting this up correctly.
The configuration consists of at least three separate support objects. Two are needed once (infinispan cache manager and clustered lock registry), whereas the other is required per unique group you have defined within the context of your runtime. So, if you have two unique group names within the runtime, you need two leader initiator support objects.
3.3.1 Infinispan Cache Manager
Given this, let us first look at the Infinispan cache manager. You can add this support object in the standard manner by searching for "infinispan cache manager."
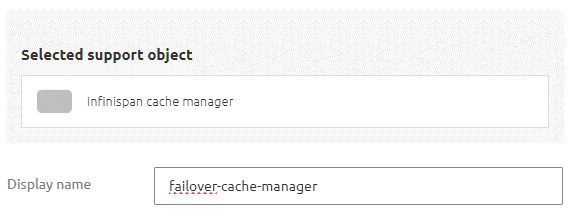
Once found, give it a name and fill in a cluster name.
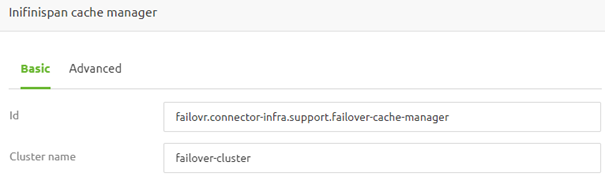
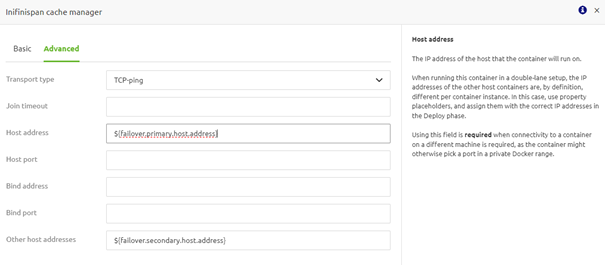
Once done, switch to the "Advanced" tab, select the option "TCP Ping," and fill in the "Host address" and "Other host addresses". Once filled in, press Save to keep your changes.
3.3.2 Clustered Lock Registry
Now that we have the cache manager, we can configure the next support object on our list, the clustered lock registry. You can add this support object in the standard manner by searching for "lock registry."
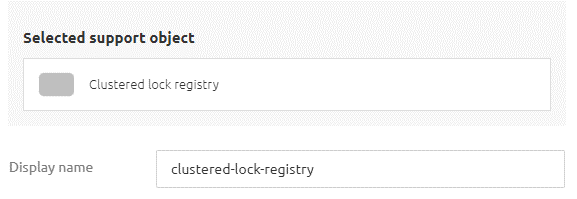
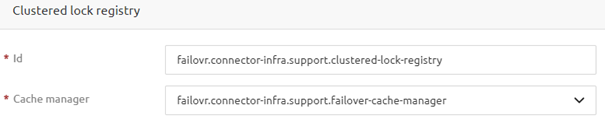
Once found, name it and select the cache manager support object you created.
3.3.3 Leader Initiator
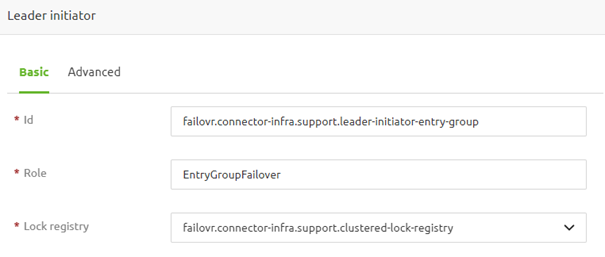
Lastly, we need to configure a leader initiator for each unique group we have defined within the context of the runtime, and that uses the failover functionality. You can add this support object in the standard manner by searching for "leader."
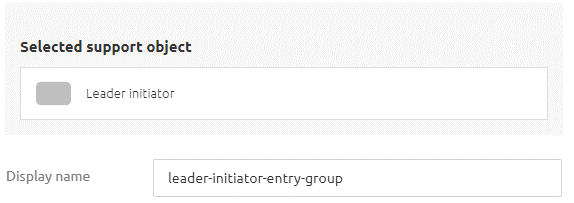
Once found, give it a name, define the role name (which should exactly match the name you gave in the inbound components), and link it to the lock registry.
4. Key takeaways
- Grouping is beneficial when external systems go through maintenance or downtime.
- Failover can have the additional benefit of having a fallback scenario while still adhering to the requirement that there can only be one active connection at a time.
- The role naming in both grouping and failover is crucial. The whole name needs to be matched fully to make it work.
- For the infra configuration of the failover setup, we have a store item that you can use.
5. Suggested Additional Readings
If you are interested in this topic and want more information, please read the help text provided by eMagiz and check out these links: