
Using Kafka Module in Mendix
In this microlearning, we will focus on how you can utilize the Kafka Module from eMagiz as available via the portal to consume and produce data from topics managed within the eMagiz Kafka Cluster. By the end, you'll have a clear understanding of setting up connections, configuring producers and consumers, and utilizing the Kafka Module to streamline data transportation between systems.
Should you have any questions, please get in touch with academy@emagiz.com.
1. Prerequisites
- Basic knowledge of the eMagiz platform
- Basic knowledge of the Mendix platform
- Mendix project in which you can test this functionality
- A Kafka cluster to which you can connect.
- Access to the eMagiz Event catalog to obtain the required Keystore & Truststore (or communication with someone that can provide you the relevant key- and truststore).
- To learn more about the eMagiz Event Catalog, please refer to the microlearning, which can be found here eMagiz Event Catalog.
2. Key concepts
This microlearning centers around using the Kafka module of eMagiz in Mendix.
- By using, in this context, we mean: Being able to produce and consume data to and from topics that are managed within an external Kafka Cluster, such as the eMagiz Kafka Cluster.
- By knowing how you can easily set up Mendix to consume and produce data from and to topics, you have the option to better transport large volumes of data between several systems (i.e., two Mendix applications).
Some key concepts before you dive further into this microlearning:
- Producing data on a topic means that the external system, in this case, Mendix, writes data to a pre-defined topic where the data is stored temporarily to ensure that one or more other systems can consume the data.
- Consuming data from a topic means that the external system, in this case, Mendix, reads data from a pre-defined topic where the data is stored temporarily.
3. Using Kafka Module in Mendix
To use the Kafka Module in Mendix, you need to be able to do at least the following:
- Set up a connection to the external Kafka Cluster (i.e., the eMagiz Kafka Cluster) from Mendix
- Configure a Producer that can write (publish) data to a topic or configure a Consumer that can read (listen) data from a topic
When you have configured these steps, you have to think about how you want to transfer data from and your data model. That part is excluded in this microlearning as that focuses solely on how you build microflows in Mendix. It is good to notice that the Kafka Module comes with some good examples of microflows that you can use as a starting point. These examples can be found in the \_USE_ME folder of the Mendix module.
3.1 Initial Configuration Kafka Module
The first step is to set up the connection to an external Kafka Cluster. Before we can configure anything, we first need to retrieve the correct Kafka Module from the Mendix marketplace.
3.1.2 eMagiz Kafka Module
The eMagiz Kafka Module is available in the Mendix Marketplace and is also made available via the portal (similar to the eMagiz Mendix Connector). If you have trouble finding the correct module, please contact productmanagement@emagiz.com.
3.1.2 Making the configuration page accessible
After you have imported the Kafka module within your project, you can take the next step.
Within the Kafka Module, there is a microflow called OpenAdministration. Ensure an admin can reach this microflow as this is the starting point for the rest of the configuration.
3.2 Set up a connection to the external Kafka Cluster
When you run your project, call the microflow. The microflow will lead you to the following page.

This page consists of three tabs. The first tab documents the steps you need to take. The second tab is for the server configuration and the producer config. The third tab is for a consumer config. We will focus our attention on setting up the connection between Mendix and the Kafka cluster in this segment. This is a prerequisite for the configuration of producers and consumers and a working solution.
To set up the general settings, first, navigate to the tab called Configuration Details. This will lead you to the following overview.

This overview holds all generic configuration elements needed to set up a connection to a Kafka cluster. Under the advanced tab, you will see the detailed configuration. You do not have to change any of these settings.
The settings you do need to change/fill in, however, are:
- bootstrap servers
- reference to Keystore and truststore, including passwords.
At first, you fill in the bootstrap server URL. If you have done so, you can continue on this page by filling in the SSL details. In this second part of the overview, we define the Truststore and Keystore needed to authenticate ourselves with the Kafka Cluster.
To retrieve the relevant details that you need to configure here, please ask your implementation contact performing the eMagiz implementation to grant you access to the catalog. For more information on the catalog, please check out this microlearning.
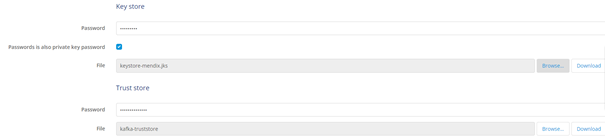
If you have received the Keystore and Truststore, you can upload them and fill in the password.
Remember, it is a best practice to ensure that the private key password of the Keystore always matches the password of the Keystore itself.
The moment you are satisfied with your configuration, press Save. This will show you a popup that the configuration has indeed been saved.
3.3 Configure a Producer
To configure a Producer, you navigate to the tab called Configuration Details. On the bottom, you have a section called Producer.

eMagiz will automatically add a producer to your server configuration filled in with all the correct detailed information. This is to make your life a little bit easier.
3.4 Configure a Consumer
To configure a Consumer, you navigate to the tab called Consumers and press the New button.
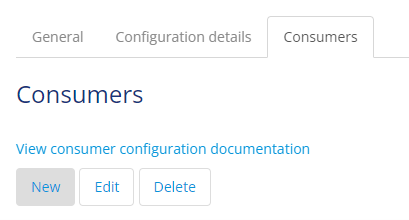
Fill in the relevant information on the General tab:
- Topic(s) from which the consumer will consume data
- Group ID for identification purposes while managing the cluster
- Reference to the on-receive microflow that will handle the incoming data
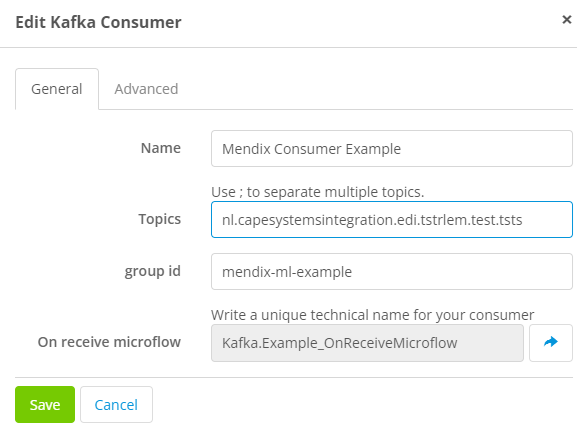
Once again, the default configuration provided under the advanced tab works, and therefore there is no need to change it.
Suppose you have done all this press Save. The result of this is that you will see a new consumer on the Consumers tab.
3.4.1 Registering a Consumer
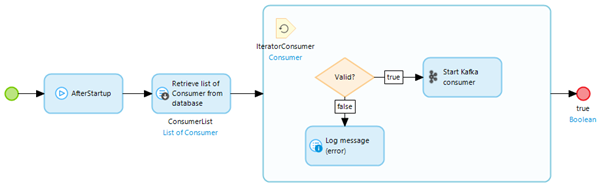
After you have configured the consumer, you will need to ensure that every time your application starts up, the consumer(s) are registered and are listening to whether new data comes in.
To do so, make sure that you retrieve the consumer(s) you have configured in the after startup microflow of your project and start them one by one. This can be easily achieved by using the microflow called AfterStartUpConsumersMicroflow, which you can find in the \_USE_ME folder of the Kafka Module as part of your own after startup microflow.
3.4.2 Multi Instance Configuration - Consumer Groups
In the consumer configuration as seen above, you will find a specific setting to identify the Group ID of this application. A Group ID identifies a consumer group. A consumer group can have more than 1 consumer that share the offset of the message consumed from that topic. In case where a application is duplicated for fail-over purposes, the group ID will ensure that each application will read message that belongs to the latest offset (so that message don't get read twice). In case consumers exist that need to read each message for a different usage or business process, you need to make sure that these Group IDs are different (each group ID has its own offset). For an explanation on how consumers groups work please see this fundamental
Congratulations, you have successfully configured Mendix to produce and consume data from and topics registered on an external Kafka cluster.
4. Key takeaways
- Start by importing the eMagiz Kafka Module from the Mendix Marketplace into your project. This module is essential for integrating with Kafka.
- Make sure that your implementation contact has given you access to the catalog so you can retrieve the relevant information (bootstrap server, Keystore, and Truststore)
- The Kafka Module provides pre-configured settings for ease of use. Typically, you don't need to modify these settings, but make sure to verify and complete the configuration according to your project's requirements.
5. Suggested Additional Readings
If you are interested in this topic and want more information on it, please see the following links: